Youtube, TikTok, Instagram… esses são alguns dos aplicativos mais utilizados nos tempos atuais, e algo que todos eles possuem em comum é a capacidade de recomendar conteúdos que sejam atrativos e relevantes para seus usuários.
Esse é o poder dos algoritmos de recomendação: eles estão presentes em praticamente todos os aplicativos que usamos no nosso dia-a-dia, aumentando o nosso engajamento e percepção de valor para com eles. Personalizar a experiência do nosso usuário já virou algo tão convencional, que é quase impossível imaginar um produto sem algoritmos de recomendação.
Trazendo para a minha realidade, de três projetos que atuo como product owner, todos os três requerem algum grau de recomendação de conteúdo para o usuário.
- UpyShop: recomendação de anúncios com base nas buscas anteriores no marketplace.
- Neezy: recomendação de imóveis e empreendimentos alinhados ao perfil de compra do usuário.
- ExpoMap: sugestão de itinerários personalizados dentro de eventos e feiras.
Foi diante desse cenário, que resolvi mergulhar de cabeça nos estudos para entender o funcionamento por trás de tais algoritmos, tema que já abordei na minha postagem anterior. Mas hoje é dia de colocar em prática os aprendizados obtidos até aqui!
Esse é o primeiro de uma série de dois posts onde compartilho minha experiência e os aprendizados obtidos ao implementar um sistema de recomendação de livros, usando um dataset disponível no Kaggle. Com sorte, você também poderá aprender um pouco mais sobre machine-learning, redes neurais e sistemas de recomendação no geral. Hoje começaremos implementando a etapa da geração de candidatos.
P.S.: Também estarei lançando o código usado nessa postagem no meu GitHub para que você possa usar como base para seus próprios estudos e reproduzir o experimento desse artigo.
1. Entendendo o problema
Conforme discutido no artigo anterior, um dos principais desafios dos sistemas de recomendação é quantificar a similaridade entre dois itens, etapa fundamental para a chamada geração de candidatos. É nela que o sistema analisa quais itens são mais parecidos com aqueles que o usuário já demonstrou interesse (no caso do content-based filtering) ou encontra usuários similares, como no collaborative filtering.
Grande parte das abordagens baseadas em aprendizado de máquina para tal problema envolve mapear cada item do conjunto de dados para um vetor em um espaço n-dimensional, conhecido como embedding.
Um embedding funciona como uma espécie de “endereçamento de itens” em um mapa: itens com características parecidas terão endereços mais próximos nesse mapa, de forma que a “vizinhança” de um item é sempre formada por outros itens semelhantes a ele.
Ao finalizar o nosso embedding, perceba que o problema de encontrar itens similares se transforma em um problema de encontrar itens próximos, portanto as métricas de similaridade nada mais são do que medidas de distância entre dois pontos no nosso espaço representativo multi-dimensional:
- Distância Euclidiana: A distância euclidiana é a distância direta entre duas entidades no espaço do vetor.
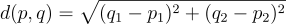
- Produto escalar dos vetores: É uma operação que resulta em um escalar e mede o grau de alinhamento entre dois vetores.

- Cosseno entre os pontos: É uma medida que avalia o ângulo entre dois vetores no espaço, indicando o quanto eles apontam na mesma direção.

Por isso, o verdadeiro desafio do nosso sistema de recomendação está em construir um bom embedding, ou seja, treinar uma rede capaz de gerar representações vetoriais que realmente capturem a essência dos itens do nosso conjunto de dados.
2. Entendendo o conjunto de dados
O conjunto de dados utilizado nesse experimento é o Book Recommendation Dataset, disponível no Kaggle. Ele é composto por 3 arquivos .csv: Books.csv, Users.csv e Ratings.csv. Vamos visualizar cada um deles:
- Books.csv: Possui dados de 271358 livros (título, autor, ano, editora) de 102022 autores, indexados pelo seu código ISBN.

- Users.csv: Possui dados de 278858 usuários (idade e localização) indexados por um User-ID.

- Ratings.csv: Relaciona usuários com livros, exibindo a nota que um usuário específico atribuiu para um livro específico, contendo 1149780 avaliações.

Porém, analisando a distribuição das avaliações, percebemos que a maior parte das avaliações do dataset contém a nota zero.

Esse tipo de distribuição pode introduzir viés durante o treinamento do modelo, já que, ao tentar minimizar o erro médio das previsões, o modelo tenderá a favorecer notas mais baixas. Isso pode prejudicar a capacidade do sistema de identificar itens realmente relevantes para o usuário.
Em um cenário real, essas notas zero provavelmente representam casos em que o usuário visualizou um livro, mas não chegou a avaliá-lo. Nesse caso, o sistema atribui automaticamente uma nota zero, o que não reflete uma opinião negativa, mas sim a ausência de avaliação.
Como esses data-points não carregam informação útil sobre a preferência do usuário, mantê-los pode confundir o modelo durante o treinamento. Por isso, podemos removê-los do nosso conjunto:
ratings_df = ratings_df[ratings_df["Book-Rating"] > 0]
O que nos resulta 383840 avaliações com a seguinte distruibuição:

Mesmo após o filtro, ainda nos deparamos com uma característica muito comum em sistemas de recomendação: a esparsidade do dataset.
Esparsidade é um termo usado para descrever a presença predominante de valores ausentes em uma matriz de dados, e pode ser calculada com:

Um dataset esparso possui a maioria de suas células vazias, ou seja, a maioria dos usuários interagiu apenas com uma pequena fração dos itens disponíveis. Essa escassez de informações dificulta a tarefa do modelo de identificar padrões e prever preferências com precisão.

Calculando a espacidade do nosso dataset com:
def compute_sparsity(df, user_col="User-ID", item_col="ISBN"):
num_users = df[user_col].nunique()
num_items = df[item_col].nunique()
num_interactions = len(df)
total_possible = num_users * num_items
sparsity = 1 - (num_interactions / total_possible)
print(f"Número de usuários: {num_users}")
print(f"Número de livros: {num_items}")
print(f"Número de interações: {num_interactions}")
print(f"Total possível de interações: {total_possible}")
print(f"Esparsidade: {sparsity:.4f} ({sparsity*100:.2f}%)")
return sparsity
Temos o resultado:
Número de usuários: 59941
Número de itens: 128920
Número de interações: 307072
Total possível de interações: 7727593720
Esparsidade: 1.0000 (100.00%)
Essa é a realidade da maioria dos sistemas de recomendação: usuários costumam interagir com apenas uma fração muito pequena do conteúdo disponível. Como consequência, trabalhamos com poucos dados explícitos por usuário, o que dificulta o aprendizado e aumenta o risco de overfitting, especialmente se utilizarmos modelos muito complexos na etapa de geração de candidatos.
Por isso, é importante optar por modelos mais leves e generalizáveis nessa etapa, garantindo que o sistema consiga escalar bem mesmo diante de uma matriz de interações altamente esparsa.
3. Deliberando sobre o modelo
Conforme mencionado anteriormente, existem duas abordagens principais para resolver o problema da geração de candidatos:
- Content-based filtering: Baseia-se nas características dos itens. O sistema recomenda itens semelhantes àqueles com os quais o usuário já interagiu, analisando atributos como gênero, autor, descrição, etc.
- Collaborative filtering: Baseia-se apenas nos padrões de interação entre usuários e itens. O sistema aprende a partir do comportamento coletivo — por exemplo, recomendando um livro que foi bem avaliado por usuários com gostos similares, mesmo que o sistema não conheça nada sobre o conteúdo do livro ou o perfil do usuário.
Neste experimento, optei por uma abordagem híbrida, combinando elementos de collaborative filtering e content-based filtering. Com isso, o modelo é capaz de aprender padrões de interação entre usuários e livros (como no collaborative filtering), ao mesmo tempo em que considera características dos próprios itens, como o autor do livro, para inferir semelhanças entre eles (como no content-based).
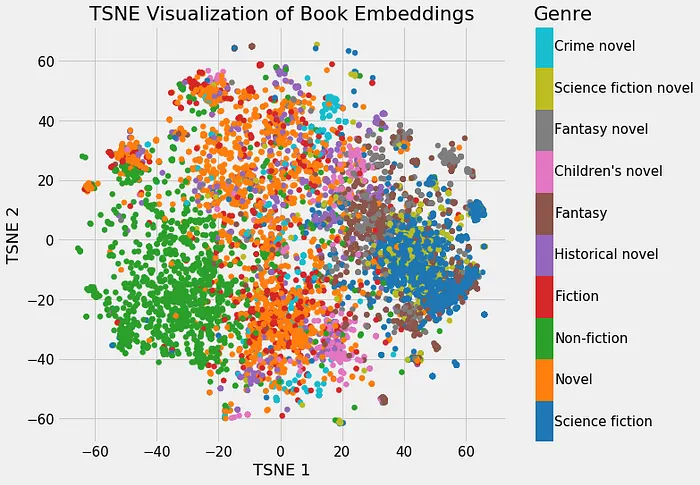
Sendo assim, o nosso modelo irá criar ao mesmo tempo um embedding para livros, autores e usuários, o que nos permitirá encontrar semelhanças entre esses três itens.
Para treinar esses embeddings, formulamos um problema intermediário (proxy) de regressão, no qual o modelo tem como objetivo prever a nota que um usuário atribuiu a um determinado livro. Durante esse processo, os embeddings de usuários, livros e autores são ajustados de forma que ajudem o modelo a minimizar o erro de previsão, resultando em representações vetoriais significativas que capturam relações relevantes entre esses elementos.
O nosso objetivo aqui é usar os embeddings para cálculo de similaridade entre itens ou usuários, e não necessariamente prever a nota com máxima precisão (isso é o objetivo da etapa de pontuação, que falaremos no próximo artigo). Por isso, o modelo utilizado será intencionalmente simples: ele será composto apenas pelas camadas de embedding e uma camada final com um único neurônio, responsável por gerar a predição da nota.

Apesar da precisão nesse modelo intermediário não ser tão importante, conseguimos treinar um modelo decentemente preciso:

4. Explorando os resultados
Ao finalizar o treinamento, podemos obter os embeddings gerados com:
book_embeddings = model.get_layer("book_embedding").get_weights()[0]
user_embeddings = model.get_layer("user_embedding").get_weights()[0]
author_embeddings =model.get_layer("author_embedding").get_weights()[0]
Com esses vetores, já é possível calcular a similaridade entre itens (como livros ou autores) por meio de uma métrica escolhida.
Um artefato comumente utilizado é a chamada matriz de similaridade, onde cada célula representa o grau de similaridade entre dois itens — quanto mais próximo de 1, mais similares eles são.

No entanto, na prática, essas matrizes se tornam inviáveis quando lidamos com grandes volumes de dados. Por exemplo, com 90 mil livros, a matriz completa de similaridade teria mais de 8 bilhões de entradas (90.000 × 90.000).
Para contornar esse problema, utilizamos uma abordagem mais escalável: em vez de gerar toda a matriz, calculamos as distâncias sob demanda, apenas entre o item de interesse e todos os outros. Assim, conseguimos encontrar os itens mais similares de forma eficiente, ordenando os resultados conforme a distância.
# Encontrando livros similares
def recommend_similar_books_fast(book_id, top_n=5):
try:
book_idx = book_encoder.transform([book_id])[0]
except:
print(“Book ID não encontrado.”)
return []
target_embedding = book_embeddings[book_idx].reshape(1, -1)
similarities = cosine_similarity(target_embedding, book_embeddings)[0]
similar_indices = similarities.argsort()[::-1][1:top_n+1]
similar_books = [book_encoder.inverse_transform([i])[0] for i in similar_indices]
scores = [round(similarities[i], 4) for i in similar_indices]
return list(zip(similar_books, scores))
# Encontrando autores similares
def recommend_similar_authors_fast(author_name, top_n=5):
try:
author_idx = author2id[author_name.lower().strip()]
except KeyError:
print(“Autor não encontrado.”)
return []
target_embedding = author_embeddings[author_idx].reshape(1, -1)
similarities = cosine_similarity(target_embedding, author_embeddings)[0]
similar_indices = similarities.argsort()[::-1][1:top_n+1]
id2author = {idx: author for author, idx in author2id.items()}
similar_authors = [(id2author[i], round(similarities[i], 4)) for i in similar_indices]
return similar_authors
# Encontrando usuários similares
def recommend_similar_users_fast(user_id, top_n=5):
try:
user_idx = user_encoder.transform([user_id])[0]
except:
print(“User ID não encontrado.”)
return []
target_embedding = user_embeddings[user_idx].reshape(1, -1)
similarities = cosine_similarity(target_embedding, user_embeddings)[0]
similar_indices = similarities.argsort()[::-1][1:top_n+1]
similar_users = [user_encoder.inverse_transform([i])[0] for i in similar_indices]
scores = [round(similarities[i], 4) for i in similar_indices]
return list(zip(similar_users, scores))
Utilizando essas funções de extração e cálculo de similaridade, conseguimos explorar os resultados gerados pelo nosso sistema de recomendação.
Eis os 10 autores que a rede identificou como mais semelhantes a Machado de Assis:
recommend_similar_authors_fast("Machado de Assis", top_n=10)
[('ahdaf soueif', np.float32(1.0)),
('liz waterland', np.float32(1.0)),
('lynn caporale', np.float32(1.0)),
('kathy kaehler', np.float32(1.0)),
('joan bauer', np.float32(1.0)),
('monique bonnet', np.float32(1.0)),
('clifton a. cross', np.float32(1.0)),
('angela carson', np.float32(1.0)),
('patricia a. taylor', np.float32(1.0)),
('susan macias', np.float32(1.0))]
Eis os 10 livros que a rede identificou como mais semelhantes a O Senhor dos Anéis — As Duas Torres:
recommended_books = recommend_similar_books_fast("0345339711", top_n=10)
for book in recommended_books:
print(convert_isbn_to_title(book[0]))
('3442720621', 'Geschehnisse am Wasser.')
('0451458370', 'Alien Taste (Roc Science Fiction)')
('0385472951', 'The Partner')
('0140075623', 'Stones for Ibarra (Penguin Contemporary American Fiction Series)')
('1562470752', 'Meet Addy: An American Girl (American Girls Collection (Paper))')
('1568654405', 'Military Book Clubs Emergency Medical')
('0312319517', 'Avenger (Forsyth, Frederick)')
('0380720191', 'The List of 7')
('0345339681', 'The Hobbit : The Enchanting Prelude to The Lord of the Rings')
('0345447581', 'Marque and Reprisal')
Vale lembrar que o principal objetivo da etapa de geração de candidatos não é medir a similaridade com máxima precisão, mas sim reduzir de forma eficiente o universo de itens disponíveis, de centenas de milhares para apenas algumas centenas, mantendo uma boa representatividade.
A precisão fina nas recomendações acontece na próxima etapa, chamada scoring, onde avaliamos de forma mais rigorosa a compatibilidade entre usuário e item.