Nesse artigo, você vai entender como funcionam os sistemas de recomendação, suas principais etapas e as abordagens mais usadas como content-based e collaborative filtering.
Terminologia
– Itens (documentos): entidades que são recomendadas por um sistema a serem consultadas.
– Consulta (context): Informações que um sistema usa para fazer recomendações.
– Embedding: mapeamento de um sistema discreto (de itens e consultas) para um espaço vetorial multi-dimensional.
Etapas do Sistema
1. Geração de candidatos: O sistema, com base em um conjunto enorme de itens, avalia os mais rapidamente, reduzindo a quantidade significativa de itens a serem considerados.
2. Pontuação: Outro modelo atribui uma pontuação para cada candidato selecionado com base no contexto. Essa etapa pode requerer um modelo mais complexo.
3. Re-ranking: Por fim, o sistema utiliza outras informações para melhorar a qualidade do ranqueamento final. Isso pode envolver a remoção de itens que o usuário explicitamente rejeitou ou aumentar a pontuação de itens mais novos, garantindo novidade e diversidade.
Geração de Candidatos
Existem dois tipos de abordagens para a geração de candidatos:
– Content-based filtering: Usa a similaridade entre itens para recomendar itens similares dos que o usuário tem interesse. Exemplo: Se o usuário A gosta de vídeos de gatinhos, o sistema pode recomendar vídeos de outros animais.
– Collaborative filtering: Usa a similaridade entre usuários para determinar quais gostos eles podem ter em comum. Exemplo: Se o usuário A é similar ao usuário B, e o usuário A é fã do vídeo 1, o sistema pode recomendar o vídeo 1 para o usuário B.
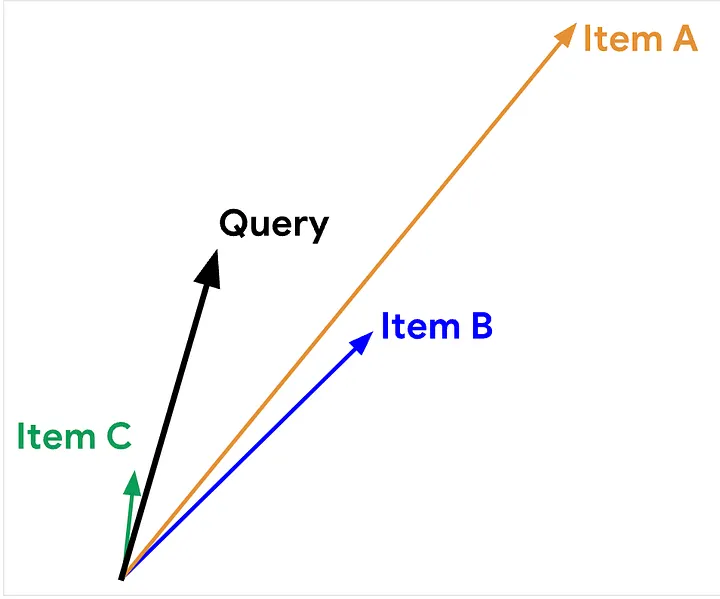
Métricas de Similaridade:
– Produto escalar: É definido pelo produto entre o módulo de dois vetores vezes o cosseno do ângulo formado entre eles.
– Cosseno: Cosseno é o ângulo entre dois vetores no espaço de embedding. No caso de um dataset com os vetores normalizados, o produto escalar tem o mesmo resultado que o cosseno, pois seu módulo sempre será 1.
– Distância Euclidiana: A distância euclidiana é a distância direta entre duas entidades no espaço do vetor.
Pontuação
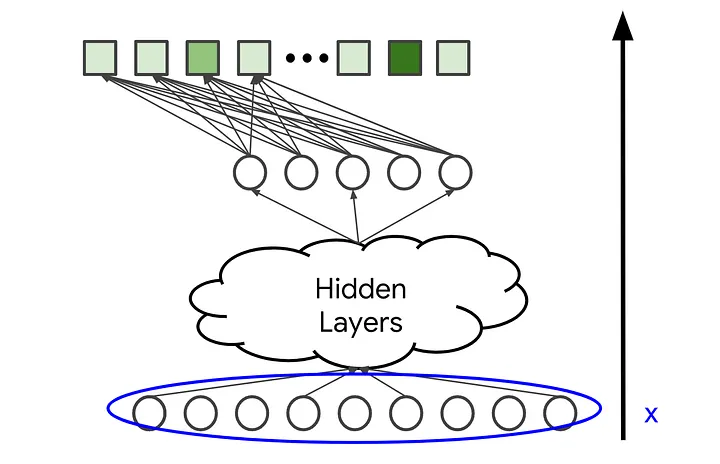
Após a geração de candidatos, o próximo passo é atribuir uma pontuação a cada item selecionado. Essa etapa envolve modelos mais sofisticados, que utilizam diversas características do usuário, do item e do contexto para determinar a relevância de um candidato.
Abordagens para Pontuação
– Modelos baseados em aprendizado de máquina: Modelos supervisionados ou não supervisionados podem ser treinados para prever a relevância de um item para um usuário específico. Exemplos incluem redes neurais, árvores de decisão e regressão logística.
– Modelos heurísticos: Algumas implementações utilizam regras definidas manualmente para atribuir pontuações, como a frequência de interação com um item ou a popularidade de um documento dentro de um determinado período.
– Modelos híbridos: Combinação de técnicas heurísticas e aprendizado de máquina para obter melhores resultados de recomendação.
Fatores Considerados na Pontuação
– Histórico do usuário: Interações passadas, cliques, tempo gasto e avaliações de itens.
– Características do item: Tipo de conteúdo, categoria, popularidade e metadata associada.
– Contexto da recomendação: Hora do dia, localização do usuário, dispositivo utilizado e preferências atuais.
A pontuação final é utilizada para definir um ranqueamento preliminar dos itens candidatos.
Re-ranking
O re-ranking é a última etapa antes de exibir as recomendações ao usuário. Essa fase aprimora a lista de itens ranqueados levando em consideração fatores adicionais, como diversidade, novidade e personalização refinada.
Fatores de Re-ranking
– Diversidade: Evita que a recomendação contenha apenas itens muito similares, garantindo variedade no conteúdo sugerido.
– Novidade: Promove itens recentemente adicionados ao sistema para estimular o consumo de novos conteúdos.
– Penalização de itens rejeitados: Itens que o usuário já rejeitou explicitamente podem ser removidos ou ter sua pontuação reduzida.
– Ajuste de preferência contextual: Refinamento do ranqueamento com base no contexto imediato do usuário, como preferência por determinado tipo de conteúdo em horários específicos.
O resultado final é uma lista otimizada de recomendações que equilibra relevância, diversidade e personalização para proporcionar a melhor experiência ao usuário.